
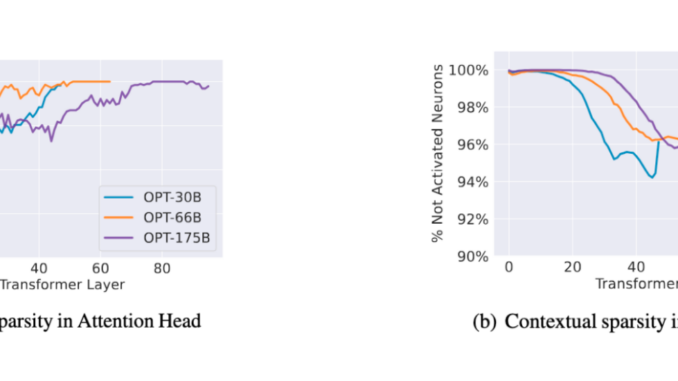
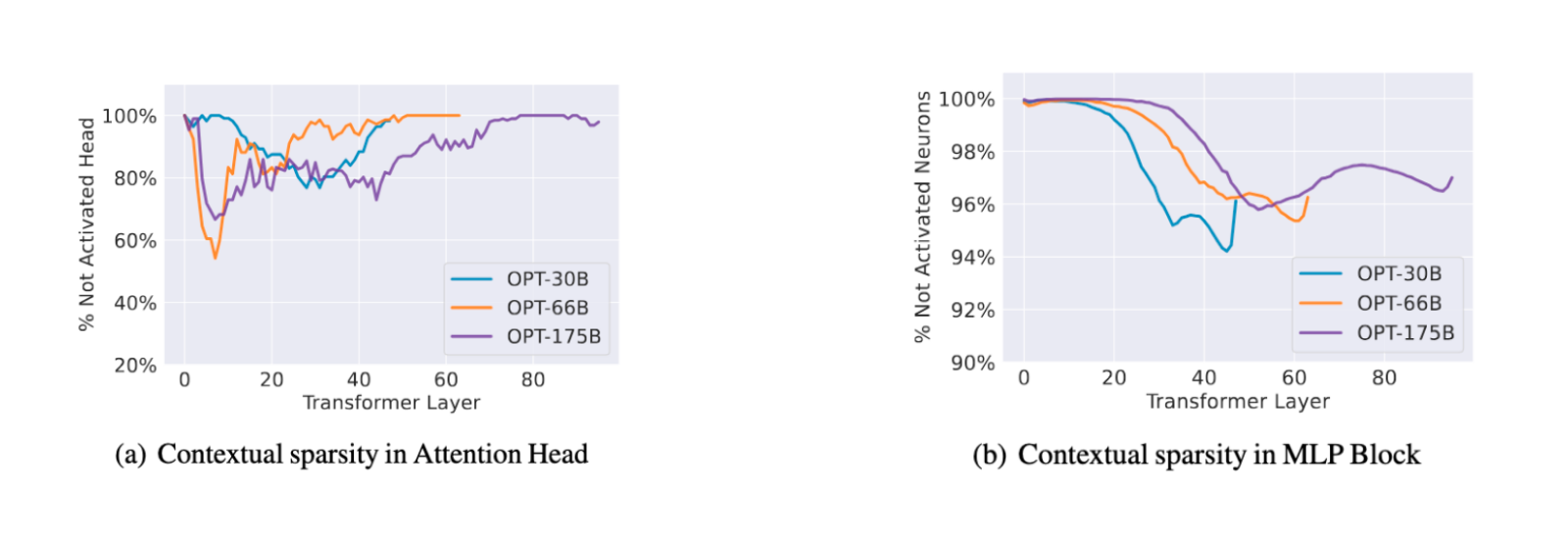
The sparsity vs quantization debate isn’t new—but in the age of Generative AI, it’s louder than ever.
At a glance, both techniques look like mathematical shortcuts to make AI models more efficient. But from a hardware architect’s point of view, they’re fundamentally different beasts—each bringing its own set of trade-offs, bottlenecks, and design headaches.
So the real question isn’t just which is better—it’s how each one reshapes the hardware underneath.
Let’s break it down.
Table of Contents
ToggleFirst, a Quick Scope
We’re focusing on compute-bound workloads—the kind that rely heavily on dense compute engines like tensor cores or MXUs.
Memory-bound scenarios are a different conversation entirely, with their own unique constraints.
Sparsity: Doing Less Work
The idea behind sparsity is simple:
If a value is zero (or close enough), skip the computation.
In theory, this can drastically cut down both compute and memory usage.
The Problem: Randomness Breaks Hardware
The most efficient form—unstructured sparsity—creates a chaotic pattern of zeros across the model.
And hardware hates chaos.
- Memory access becomes irregular
- Load balancing across cores gets unpredictable
- Cache efficiency drops
- SIMD units sit idle waiting for data
To deal with this, early sparse accelerators (like EIE and SCNN) had to introduce complex routing systems, crossbars, and buffering layers—often increasing hardware overhead just to keep things running smoothly.
The Industry Shift: Structured Sparsity
To make sparsity practical, the industry introduced structure.
Techniques like N:M sparsity (used in NVIDIA Ampere) enforce a fixed ratio of non-zero values within blocks. This makes scheduling predictable and hardware-friendly.
More recently, block-level sparsity has gained traction—especially for large language models:
- Block-Sparse Attention
- Routing Attention
- StreamingLLM
Instead of skipping individual elements, these approaches skip entire chunks of computation. That keeps memory access contiguous and compute units fully utilized.
The Trade-Off
You gain predictability—but lose some theoretical efficiency.
There’s also a cost:
- Extra metadata (indices)
- Additional control logic
- Risk of dropping important information
Quantization: Doing Smaller Work
If sparsity reduces how much you compute, quantization reduces how heavy each computation is.
It works by shrinking data precision:
- FP32 → INT8
- Even down to 4-bit, 2-bit, or 1-bit representations
Modern techniques like BitNet (1-bit) and GPTQ (2-bit) show that even extreme compression can preserve surprising accuracy.
The Problem: Metadata Explosion
The challenge with quantization isn’t just lower precision—it’s everything that comes with it.
To maintain accuracy, you need:
- Per-channel or per-token scaling factors
- Dynamic adjustments
- Higher-precision accumulators (FP16/FP32)
Ironically, as the data gets smaller, the overhead of managing it grows.
You end up adding:
- Extra logic for scaling
- Complex pipelines for de-quantization
- Support for dynamic quantization schemes
In some cases, this overhead can eat into the performance gains.
The Workaround: Algorithmic Offloading
To keep hardware simpler, much of the complexity is pushed into software.
Techniques like:
- SmoothQuant (shifts complexity into weights)
- AWQ (Activation-aware Weight Quantization)
…handle the hard parts during preprocessing, allowing hardware to run more uniform, low-precision operations.
The Trade-Off
This works—but introduces new risks:
- Heavy reliance on calibration datasets
- Poor handling of out-of-distribution inputs
- Limited adaptability at runtime
In short, you gain efficiency but lose flexibility.
Can You Combine Both?
In theory, yes.
In practice? It’s complicated.
The classic Deep Compression work showed that sparsity and quantization can work together. But scaling that approach to modern LLMs (think 70B+ parameters) is extremely challenging.
You run into a familiar problem:
Hardware doesn’t support it because software doesn’t use it.
Software doesn’t use it because hardware doesn’t support it.
So, What’s the Way Forward?
For hardware architects, the answer isn’t picking sides—it’s designing for both.
1. Hardware-Software Co-Design
Close collaboration is essential. New algorithms should align with hardware capabilities from day one—especially around metadata handling and data formats.
2. Unified Compression Thinking
Sparsity and quantization shouldn’t be treated as separate features.
They’re part of a broader compression spectrum.
Future architectures may:
- Use sparsity during memory-heavy phases
- Switch to ultra-low precision during compute-heavy phases
- Reuse shared hardware paths for both
3. Balance Efficiency with Flexibility
Over-optimizing for today’s techniques risks becoming obsolete tomorrow.
Hardware must remain programmable enough to support evolving ML methods.
Final Take
There’s no single winner in the sparsity vs quantization debate.
And there probably never will be.
In the era of Generative AI, the smarter question is:
How do we design systems that can adapt to both?
Because the future of AI hardware isn’t about choosing one technique over the other—it’s about building architectures flexible enough to handle the full spectrum of optimization.