
Over the next few years, most content on Netflix will come from Netflix’s own Studio. From the moment a Netflix film or series is pitched and long before it becomes available on Netflix, it goes through many phases. This happens at an unprecedented scale and introduces many interesting challenges; one of the challenges is how to provide visibility of Studio data across multiple phases and systems to facilitate operational excellence and empower decision making. Netflix is known for its loosely coupled microservice architecture and with a global studio footprint, surfacing and connecting the data from microservices into a studio data catalog in real time has become more important than ever.
Operational Reporting is a reporting paradigm specialized in covering high-resolution, low-latency data sets, serving detailed day-to-day activities and processes of a business domain. Such a paradigm aspires to assist front-line operations personnel and stakeholders in performing their tasks through means such as ad hoc analysis, decision-support, and tracking (of tasks, assets, schedules, etc). The paradigm spans across methods, tools, and technologies and is usually defined in contrast to analytical reporting and predictive modeling which are more strategic (vs. tactical) in nature.
At Netflix Studio, teams build various views of business data to provide visibility for day-to-day decision making. With dependable near real-time data, Studio teams are able to track and react better to the ever-changing pace of productions and improve efficiency of global business operations using the most up-to-date information. Data connectivity across Netflix Studio and availability of Operational Reporting tools also incentivizes studio users to avoid forming data silos.
The Journey
In the past few years, Netflix Studio has gone through few iterations of data movement approaches. In the initial stage, data consumers set up ETL pipelines directly pulling data from databases. With this batch style approach, several issues have surfaced like data movement is tightly coupled with database tables, database schema is not an exact mapping of business data model, and data being stale given it is not real time etc. Later on, we moved to event driven streaming data pipelines (powered by Delta), which solved some problems compared to the batch style, but had its own pain points, such as a high learning curve of stream processing technologies, manual pipeline setup, a lack of schema evolution support, inefficiency of onboarding new entities, inconsistent security access models, etc.
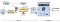
With the latest Data Mesh Platform, data movement in Netflix Studio reaches a new stage. This configuration driven platform decreases the significant lead time when creating a new pipeline, while offering new support features like end-to-end schema evolution, self-serve UI and secure data access. The high level diagram below indicates the latest version of data movement for Operational Reporting.

For data delivery, we leverage the Data Mesh platform to power the data movement. Netflix Studio applications expose GraphQL queries via Studio Edge, which is a unified graph that connects all data in Netflix Studio and provides consistent data retrieval. Change Data Capture(CDC) source connector reads from studio applications’ database transaction logs and emits the change events. The CDC events are passed on to the Data Mesh enrichment processor, which issues GraphQL queries to Studio Edge to enrich the data. Once the data has landed in the Iceberg tables in Netflix Data Warehouse, they could be used for ad-hoc or scheduled querying and reporting. Centralized data will be moved to third party services such as Google Sheets and Airtable for the stakeholders. We will deep dive into Data Delivery and Data Consumption in the following sections.
Data Delivery via Data Mesh
What is Data Mesh?
Data Mesh is a fully managed, streaming data pipeline product used for enabling Change Data Capture (CDC) use cases. In Data Mesh, users create sources and construct pipelines. Sources mimic the state of an externally managed source — as changes occur in the external source, corresponding CDC messages are produced to the Data Mesh source. Pipelines can be configured to transform and store data to externally managed sinks.
Data Mesh provides a drag-and-drop, self-service user interface for exploring sources and creating pipelines so that users can focus on delivering business value without having to worry about managing and scaling complex data streaming infrastructure.
CDC and data source
Change data capture or CDC, is a semantic for processing changes in a source for the purpose of replicating those changes to a sink. The table changes could be row changes (insert row, update row, delete row) or schema changes (add column, alter column, drop column). As of now, CDC sources have been implemented for data stores at Netflix (MySQL, Postgres). CDC events can also be sent to Data Mesh via a Java Client Producer Library.
Reusable Processors and Configuration Driven
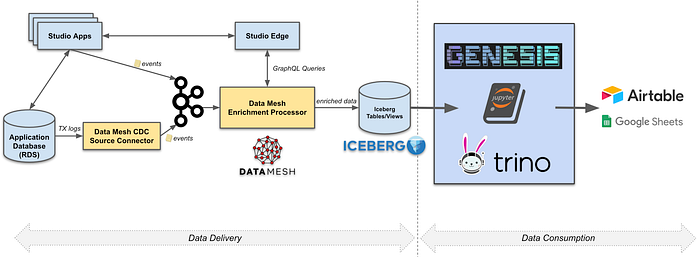
In Data Mesh, a processor is a configurable data processing application that consumes, transforms, and produces CDC events. A processor has 1 or more inputs and 0 or more outputs. Processors with 0 outputs are sink connectors; which write events to externally managed sinks (e.g. Iceberg, ElasticSearch, etc).

Data Mesh allows developers to contribute processors to the platform. Processors are not necessarily centrally developed and managed. However, the Data Mesh platform team strives to provide and manage the most highly leveraged processors (e.g. source connectors and sink connectors)
Processors are reusable. The same processor image package is used multiple times for all instances of the processor. Each instance is configured to fit each use case. For example, a GraphQL enrichment processor can be provisioned to query GraphQL Services to enrich data in different pipelines; an Iceberg sink processor can be initialized multiple times to write data to different databases/tables with different schema.
End-to-End Schema Evolution
Schema is a key component of Data Mesh. When an upstream schema evolves (e.g. schema change in the MySQL table), Data Mesh detects the change, checks the compatibility and applies the change to the downstream. With schema evolution, Data Mesh ensures the Operational Reporting pipelines always produce data with the latest schema.
We will cover a few core concepts in the Data Mesh Schema domain.
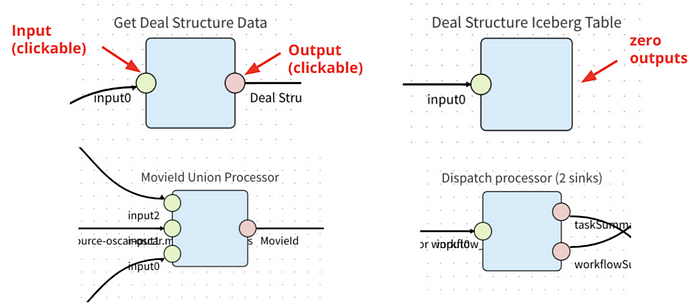
Consumer schema
Consumer schema defines how data is consumed by the downstream processors. See example below.

Schema Compatibility
Data Mesh uses Consumer Schema compatibility to achieve flexible yet safe schema evolution. If a field consumed by an Operational Reporting pipeline is removed from CDC source, Data Mesh categorizes this change as incompatible, pauses the pipeline processing and notifies the pipeline owner. On the other hand, if a required field is not consumed by any consumer, dropping such fields would be compatible.
Two Types of Processors
1. Pass through all fields from upstream to downstream.
- Example: Filter Processor, Sink Processors


2. Only uses a subset of fields from upstream.
- Example: Project Processor, Enrichment Processor

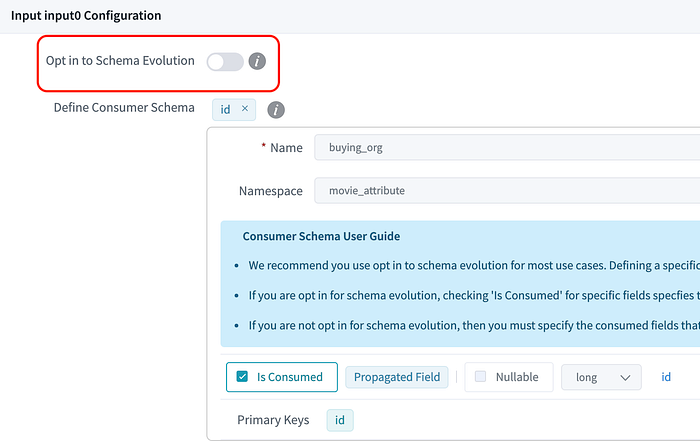
In Data Mesh, we introduce the Opt-in to Schema Evolution boolean flag to differentiate those two types of use cases.
- Opt in: All the upstream fields will be propagated to the processor. For example, when a new field is added upstream, it will be propagated automatically.
- Opt out: Only a subset of fields (defined using ‘Is Consumed’ checkboxes) is propagated and used in the processor. Upstream changes to the rest of the fields won’t affect this processor.
[“source=netflixtechblog”]